*Definición de las computadoras y sus componentes.
*Exploración de las funciones de la computadora.
*Clasificación de las computadoras y las Redes de computadoras.
*Descripción de dispositivos periféricos en una computadora.
*Dispositivos apuntadores (Ratón, Esfera y Lápiz)
*Estudio de los teclados.
*Empleo de interfaces gráficas “amigables con el usuario” GUI
DEFINICIÓN DE LAS COMPUTADORAS Y SUS COMPONENTES
Computadora es un dispositivo electrónico que acepta datos de entrada, los procesa, los almacena y los emite como salida para su interpretación. La computadora es parte de un sistema de computación. Como el que se ilustra a continuación. (Figura 1)

Un SISTEMA DE COMPUTACIÓN está conformado por hardware, periféricos y software. Tal como se ilustra en la figura 1.
HARDWARE incluye todos los dispositivos eléctricos, electrónicos y mecánicos (que se pueden ver y tocar) que se utilizan para procesar los datos. La computadora es parte del hardware del sistema de computación.
PERIFÉRICOS son los dispositivos de hardware que se encuentran alrededor de la computadora con la finalidad de aumentar las posibilidades de acceso, almacenamiento y salida del equipo de cómputo. Incluyen los dispositivos de Entrada y los de Salida.
DISPOSITIVOS DE ENTRADA son periféricos cuya función es la de reunir y traducir los datos de entrada a una forma que sea aceptable para la computadora. Los dispositivos de entrada más comunes son el teclado y el ratón o “mouse” (ver Figura 1)
DISPOSITIVOS DE SALIDA son periféricos que representan, imprimen o transfieren los resultados del procesamiento, extrayéndolos de la Memoria Principal de la computadora. Entre los dispositivos de salida más utilizados se encuentran el Monitor o Pantalla y la Impresora.
SOFTWARE – o programas – es el conjunto de instrucciones electrónicas para controlar el hardware de la computadora.
Algunos Programas existen para que la Computadora los utilice como apoyo para el manejo de sus propias tareas y dispositivos.
Otros Programas existen para que la Computadora le dé servicio al Usuario. Por ejemplo, la creación de documentos electrónicos que se imprimen.
DATOS se refieren a los elementos crudos (materia prima) que la computadora puede manipular, para convertirlos en resultados o datos procesados, conocidos como información (producto terminado). Los datos pueden consistir en letras, números, sonidos o imágenes. Independiéntemente del tipo de datos que sean, la computadora los convierte en números para procesarlos. Por lo tanto, los datos computarizados son digitales, lo que significa que han sido reducidos a dígitos o números. Los datos se guardan en medios de almacenamiento auxiliar como parte de archivos.
ARCHIVOS DE COMPUTADORA son conjuntos de datos interrelacionados a los que se les ha asignado un nombre. Los archivos pueden contener conjuntos de datos o instrucciones de programa. Un archivo que contiene datos que el usuario puede abrir y utilizar a menudo se llama documento. Un documento de computadora puede incluir muchas clases de datos, tales como: Un archivo de texto (como una carta); un grupo de números (como un presupuesto); un fragmento de video (que incluya imágenes y sonidos, como un “video clip”). Los programas de computadora (software) también se organizan en archivos, pero debido a que no se consideran texto, no son archivos de documentos.
USUARIO es toda persona que interactúa con la computadora para proporcionar datos de entrada o para obtener resultados del sistema de cómputo, que normalmente se despliegan por Pantalla o se imprimen a través de la Impresora.
Dos componentes manejan el procesamiento de datos en una computadora: la Unidad Central de Procesamiento o CPU y la Memoria Principal RAM. Ambos componentes se localizan en la Tarjeta Principal del Sistema o MOTHERBOARD, también conocida como Tarjeta Madre, porque es el tablero de circuitos que conecta la CPU a todos los otros dispositivos de hardware.
UNIDAD CENTRAL DE PROCESAMIENTO o CPU
Es el cerebro de la computadora, ya que en él se manipulan los datos. En una computadora personal o PC, la CPU entera está contenida en un pequeño chip llamado microprocesador. Cada CPU tiene dos partes fundamentales: la Unidad de Control (Control Unit) y la Unidad Aritmético-Lógica (Arithmetical-Logical Unit ALU).
UNIDAD DE CONTROL
Es el centro de administración de los recursos de la computadora (como un fiscal de tránsito). Es el centro de logística en el CPU. La Unidad de Control tiene incorporadas las instrucciones o conjunto de instrucciones. Éstas enumeran todas las operaciones que puede realizar la CPU. Cada instrucción en el juego de instrucciones es expresada en microcódigo, el cual consta de una serie de direcciones básicas que le dicen al CPU cómo ejecutar operaciones más complejas.
UNIDAD ARITMETICO - LOGICO
En esta Unidad se realizan las Operaciones Aritméticas (Suma “+”, Resta “-“, Multiplicación “x”, División “/”, Elevar a Potencia “^”) y las Operaciones Lógicas tales como igual a, no igual a ; mayor que, no mayor que ; menor que, no menor que ; mayor que o igual a, no mayor que ni igual a ; menor que o igual a, no menor que ni igual a.
Muchas instrucciones realizadas por la Unidad de Control involucran tan sólo mover datos de un lugar a otro; de RAM al Almacenamiento Auxiliar (por ejemplo Disco Duro); de RAM a la Impresora o a la Pantalla y así sucesivamente. No obstante, cuando la Unidad de Control encuentra una instrucción que implica aritmética o lógica, pasa esa instrucción a la Unidad Aritmético-Lógica o UAL. En la UAL se encuentran un grupo de registros, que son ubicaciones de memoria de alta velocidad construidas directamente en la CPU, las cuales se utilizan para conservar los datos que se están procesando en ese momento. Por ejemplo, la Unidad de Control podría cargar “dos números desde la Memoria RAM” a los registros de la ULA. Después podría pedirle a la ULA que “divida los dos números” (una operación aritmética) o que “determine si los números son iguales” (una operación lógica).
MEMORIA PRINCIPAL O MEMORIA RAM (Random Access Memory)
Es el dispositivo de almacenamiento principal en tiempo real donde se guardan los datos y programas mientras se están utilizando. La RAM consiste de chips, ya sea en la Tarjeta Madre o en un pequeño tablero de circuitos conectados a ésta. La CPU contiene las instrucciones básicas necesarias para operar la computadora, pero no tiene capacidad suficiente para almacenar programas enteros o conjuntos grandes de datos de manera permanente, por tanto, se apoya en la RAM para esta importante función de almacenar y recuperar datos con gran rapidez.
La Memoria RAM es de acceso aleatorio y de naturaleza volátil ya que pierde su contenido cuando se apaga la computadora.
La CPU está conectada a dos clases de memoria: la RAM que es volátil, y la ROM, que es no volátil (conserva los datos que contiene, aun cuando la computadora esté apagada).
CLASIFICACIÓN DE LAS COMPUTADORAS Y LAS REDES DE COMPUTADORAS.
Las computadoras con base en su tamaño y precio se clasifican en cuatro grandes categorías, a saber: Microcomputadoras, Minicomputadoras, Mainframes y Supercomputadoras.
Microcomputadora o PC es el tipo más común de computadora, por eso se le llama Computadora Personal, por estar diseñada para ser utilizada por una sola persona a la vez. A pesar de su pequeño tamaño, la PC moderna es más potente que cualquiera de las computadoras de las décadas de 1950 a 1960. (Ver Figura 1). Han llegado a ser tan fundamentales para la sociedad del siglo XXI, que sin ellas la economía mundial se detendría. Son herramientas tan flexibles y poderosas que la mayoría de las personas en el mundo de las actividades económicas de los sectores públicos, privados, ONG’s, Cooperativas, PYMES las utilizan normalmente.
Aunque no se trabaje en una entidad económica, las computadoras nos afectan todos los días. Cada vez que vamos al banco, renovamos una suscripción, pedimos información de un número telefónico, etc., nos estamos beneficiando con el poder, ubicuidad, y la velocidad de las computadoras. Incluso, al comprar comestibles, medicinas, o gasolina, interactuamos con computadoras.
Minicomputadoras son algo mayores que las PC y casi siempre las usan empresas e instituciones en formas específicas, como el procesamiento de la nómina. Estos aparatos pueden ejecutar las tareas de muchos usuarios desde una CPU Central a la que se conectan terminales los cuales son dispositivos de entrada y salida (parecidos a un PC pero sin capacidad de cómputo), dotados de un teclado, una Pantalla y el cable de conexión al CPU Central. Transmiten las solicitudes de proceso a la Minicomputadora, la cual realiza el proceso de los datos y envía el resultado al terminal correspondiente. La Impresora de la Minicomputadora realiza el trabajo de impresión para todos los Usuarios conectados por terminal. El Dispositivo de Almacenamiento de la Minicomputadora contiene los datos para todos los usuarios en un solo lugar.
Las Minicomputadoras tienden a desaparecer ante el crecimiento de la capacidad de cómputo distribuido en las Redes de Computadoras.
Mainframes o Computadoras Centrales son grandes, rápidas y bastante costosas. Frecuentemente, son utilizadas por empresas privadas y oficinas gubernamentales para centralizar el almacenamiento, procesamiento y administración de grandes cantidades de datos, y estar en capacidad de proporcionar estos datos a petición de muchos usuarios conectados. Son el sistema preferido cuando se requieren: confiabilidad, seguridad en los datos y control centralizado. La computadora central ejecuta tareas de procesamiento para muchos usuarios, quienes introducen sus peticiones desde sus terminales. Para procesar grandes cantidades de datos, suelen tener múltiples CPUs: Un CPU dirige las operaciones generales, otro CPU maneja la comunicación con todos los usuarios que solicitan datos; un tercer CPU localiza los datos solicitados en Bases de Datos.Figura 4 Computadora Mainframe En la gráfica podemos observar el tamaño relativo de una computadora Mainframe en un ambiente típico de trabajo en el sector público y en grandes empresas, que requieren simultáneamente: confiabilidad, seguridad de la data y control centralizado.
En la gráfica podemos observar el tamaño relativo de una computadora Mainframe en un ambiente típico de trabajo en el sector público y en grandes empresas, que requieren simultáneamente: confiabilidad, seguridad de la data y control centralizado.
 SUPERCOMPUTADORAS
SUPERCOMPUTADORAS
Constituyen el tipo más grande, rápido y costoso de estos aparatos. Contrario a los Minicomputadores y las Computadoras Mainframe, no son diseñados para optimizar el procesamiento de múltiples usuarios; utilizan su gran poder de cómputo en la solución de problemas muy complejos, como la predicción del clima, modelar reacciones nucleares, o control de vuelos espaciales. La velocidad de una Supercomputadora puede llegar a superar los “miles de millones de instrucciones por segundo”.
REDES DE COMPUTADORAS
Una Red es un conjunto de computadoras y otros dispositivos que se comunican entre sí para compartir datos, hardware y software. En las empresas, las redes han revolucionado el uso de la tecnología computacional, hasta el punto de que es creciente la tendencia al reemplazo de computadoras Mainframe y sus terminales por Redes Computacionales en las que cada empleado que necesita una computadora para trabajar, tiene una computadora personal conectada a la red. Ahora, la tecnología computacional y la habilidad para utilizarlas “ya no están centralizadas en la computadora Mainframe y el Personal del Departamento de Informática y Sistemas” de las empresas usuarias de las Nuevas Tecnologías de la Información y la Comunicación (NTIC). La tecnología y la habilidad para utilizarla son distribuidos dentro de la organización a través de una red de computadoras y usarios entrenados en computación.
En la educación, también han cambiado a estrategias diseñadas con base en computadoras personales en red. Esto incluye las Redes de Área Local (LAN) dentro de un área relativamente limitada, como un edificio o una universidad, donde se conectan las computadoras e impresoras en un laboratorio de computación, y las Redes de Área Amplia (WAN) que abarca una gran zona geogáfica entre ciudades, regiones, o países, como es el caso de Internet.
Los cuatro grandes beneficios involucrados en el uso de las Redes Computacionales son:
• Permitir el acceso simultáneo a programas e información muy importantes (Sin una red que permita compartir archivos los empleados tienen que guardar copias separadas de información en diferentes discos duros, información que se vuelve muy difícil de actualizar).
• Permitir a la gente compartir equipos periféricos, como impresoras y escáners.
• Hacer más eficiente la comunicación personal a través del correo electrónico (e-mail).
• Facilitar el proceso de respaldo (En las organizaciones públicas y privadas la información es extremadamente valiosa, por lo cual es imperativo tener la seguridad de los empleados respalden su información computarizada. Esto se operacionaliza mediante un dispositivo de almacenamiento común al cual los usuarios puedan accesar a través de una red con base en los niveles de autorización respectivos).
ESQUEMA DE COMUNICACIÓN ENTRE COMPUTADORAS
En un esquema básico de comunicación entre computadoras como el siguiente: (Figura 6)
AP = Aplicación SDC = Sistema de Comunicación
Fuente: Adaptado de Fred Halsall (Comunicación de Datos, redes de computadoras y sistemas abiertos, p. 4)
Si la Comunicación Usuario – Usuario es para transferir un archivo de datos de un computador a otro parecido situado en el mismo piso de oficina o en la misma habitación, el recurso de comunicación ha de ser más sencillo (por ejemplo, el recurso de transmisión puede consistir en un sencillo cable de enlace punto a punto) que el requerido para transferir datos entre computadores diferentes situados en distintas localidades.
Cuando la Comunicación Computador – Computador ocurre entre computadores ubicados en diferentes partes de una ciudad, país o región, se precisa la utilización de recursos de portadora pública. Generalmente, esto implica la red telefónica pública conmutada –PSTN: public switched telephone network- para lo cual se requiere un dispositivo conocido como módem para transmitir los datos.
Si en la aplicación intervienen más de dos computadoras, se necesita un recurso de comunicación conmutado (red) para que todos los computadores puedan comunicarse entre sí en momentos diferentes (Comunicación Computador – Red). Cuando los computadores y otros dispositivos, se encuentran distribuidos físicamente en un área relativamente pequeña (en una sola oficina o en un solo edificio) y están conectados por un enlace de comunicaciones que permite que cada dispositivo pueda interactuar con cualquier otro de la red, estamos hablando de una red que el propio usuario puede instalar. A este tipo de redes se les llama red de área local (LAN: local area network). En el mercado informático existe una extensa gama de redes LAN y de equipos asociados.
Cuando los computadores están ubicados en diferentes localidades geográficas, se requieren los recursos de las portadoras públicas para unir los diversos segmentos de la red. A la red así configurada se le conoce como red de área extensa (WAN: wide area network) Una WAN puede ser una red local grande, o puede estar formada por una serie de LAN (redes de área local) conectadas entre sí.
El tipo de WAN que se utilice dependerá de la naturaleza de la aplicación. Por ejemplo, cuando todos los computadores pertenecen a la misma empresa y se requiere transferir un elevado volumen de datos entre localidades, una estrategia podría consistir en alquilar líneas o circuitos de transmisión de portadoras públicas e instalar un sistema de conmutación privado en cada localidad para crear lo que se conoce como red privada corporativa, en la cual se integran comunicaciones de voz y datos. Muchas grandes empresas aplican este enfoque por razones de políticas corporativas a nivel mundial. Este tipo de soluciones sólo está al alcance de las grandes empresas nacionales y multinacionales, debido a que el tráfico entre localidades es suficientemente voluminoso para justificar el costo de alquilar líneas de comunicación, la instalación y mantenimiento de una red privada. En la mayoría de los demás casos es necesario utilizar las redes de portadora pública. Éstas proporcionan un servicio telefónico público conmutado, además casi todas las portadoras públicas ofrecen servicios de datos conmutados, conexiones internacionales y se diseñan específicamente para transmitir datos más que voz. Halsall (1998) Consecuentemente, para redes WAN con localidades nacionales, regionales y/o internacionales, lo que suele utilizarse como solución es una red de datos conmutada (PSDN: public switched data network).
Muchas portadoras públicas ya han convertido sus PSTN existentes para poder transmitir datos sin modems. Con lo cual, las redes resultantes que funcionan de modo totalmente digital, se conocen como redes digitales de servicios integrados (ISDN: integrated services digital networks). Las ISDN, según el Diccionario de Informática e Internet, Microsoft (2001) son “Redes digitales de comunicaciones a nivel mundial surgidas a partir de los servicios telefónicos existentes. El objetivo de ISDN o RDSI (Red Digital de Servicios Integrados) es reemplazar la red telefónica actual, que requiere la conversión de digital a analógico, con facilidades totalmente dedicadas al intercambio y la transmisión digitales, música y video. RDSI está construido a partir de dos tipos principales de canales de comunicación: un canal B, que transporta datos a una velocidad de 64Kbps (kilobits por segundo), y un canal D, que transporta información de control a 16 o 64 Kbps. Las computadoras y otros dispositivos se conectan a líneas RDSI mediante interfaces estandarizados simples. Cuando esté completamente implementado (posiblemente a comienzos del nuevo milenio), se espera que RDSI proporcione a los usuarios servicios de comunicación más amplios y rápidos”.
Halsall (1998) “Las redes que hemos analizado hasta ahora se han diseñado primordialmente para transmitir datos entre estaciones de trabajo que manejan servicios exclusivamente de datos. Recientemente han aparecido estaciones de trabajo que proporcionan servicios en los que no sólo intervienen datos, sino también una diversidad de tipos de información distintos. Entre ellas están las estaciones de escritorio que permiten aplicaciones de videotelefonía, videoconferencias y servicios multimedia más generales. A fin de sustentar este conjunto de servicios más abundante, ha aparecido una nueva generación de redes denominadas redes multiservicio de banda ancha; el término -banda ancha- se usa en virtud de sus grandes velocidades de transmisión de bits.” (p. 9).
En la Venezuela del 2005, ya están disponibles estos servicios a través de CANTV, TELCEL y otros proveedores de servicios de comunicaciones de “estado del arte”, como se evidencia en la abundante promoción de esos servicios a través de los medios de comunicación masivos (Radio, Televisión, Internet, Prensa y publicaciones especializadas, e incluso a través de los servicios de Telefonía y Móviles Celulares en sus diversas encarnaciones).
TOPOLOGÍAS DE RED PARA REDES DE ÁREA LOCAL (LAN)
TOPOLOGÍA (topology) s. La configuración formada por las conexiones entre los dispositivos en una red de área local (LAN) o entre dos o más LAN. Véase también red en bus, LAN, red en anillo, red en estrella, red en anillo con testigo, red en árbol.
Microsoft Diccionario de Informática e Internet (2001).
DISEÑO DE UNA TOPOLOGÍA DE RED
La topología de red se refiere a la organización o distribución física de los equipos, cables y otros componentes de la red. El término Topología es la denominación estándar que utilizan los profesionales de las redes al referirse al Diseño Básico de la Red. Además del término topología existen otros términos que se utilizan para definir el diseño de una red:
• Esquema físico.
• Diseño.
• Diagrama.
• Mapa.
La topología de una red afecta sus capacidades, por lo tanto, la selección de una topología tendrá impacto sobre:
• El tipo de equipamiento que necesita la red.
• Las capacidades del equipo.
• El crecimiento de la red.
• Las formas de gestionar la red.
Es importante considerar que antes de que los equipos puedan compartir recursos o realizar otras tareas de comunicaciones, necesitan estar conectados sus componentes. En la mayoría de las redes se utilizan cables para conectar un equipo a otro Las cuatro topologías básicas de las redes son:
Bus Consta de dispositivos conectados a un cable común compartido.
Estrella Es la conexión de equipos a segmentos de cable que arrancan de un punto único, o hub (concentrador).
Anillo Es la conexión de equipos en un único circuito de cable.
Malla En esta topología cada equipo está conectado a todos los demás equipos mediante cables separados
Estas cuatro topologías pueden combinarse obteniendo una variedad de topologías híbridas más complejas, tales como Estrella-bus, Estrella-anillo.
Nota: La topología física de una red es el propio cable, mientras que la topología lógica de la red es la forma en que se transmiten las señales por el cable.
 RED EN BUS (bus network):
RED EN BUS (bus network):
Red de área local en la que todos los nodos están conectados a una línea de comunicaciones principal (bus). En una red en bus, cada nodo controla la actividad de la línea (nodo: En redes LAN, un dispositivo que se conecta a la red y es capaz de comunicar con otros dispositivos de la red). Los mensajes son detectados por todos los nodos pero sólo son aceptados por los nodos a los que van dirigidos. Un nodo que funciona mal deja de comunicar pero no interfiere en la operación (como podría ser el caso en una red circular en la que se trasladan los mensajes de un nodo al siguiente). Para evitar las colisiones que ocurren cuando dos o tres nodos intentan utilizar la línea a la vez, las redes de bus dependen por lo general de la detección de las colisiones o el paso de señales para regular el tráfico.
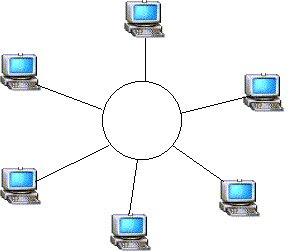 RED EN ANILLO (ring network):
RED EN ANILLO (ring network):
Red de área local en la que los dispositivos (nodos) están conectados en un lazo cerrado, o anillo. Los mensajes de una red en anillo pasan alrededor de todo el anillo de nodo en nodo, en una sola dirección. Cuando un nodo recibe un mensaje, examina la dirección de destino asociada al mismo. Si la dirección es la misma que la del nodo, éste acepta el mensaje; en caso contrario, vuelve a generar la señal y pasa el mensaje al siguiente nodo del anillo. Esta regeneración permite que una red en anillo pueda recorrer distancias más largas que las redes en bus y en estrella. El anillo puede estar configurado además para pasar por alto cualquier mal funcionamiento o fallo de un nodo. Sin embargo, dado que se trata de un lazo cerrado, puede resultar difícil incorporar nuevos nodos. Véase paso de testigo, red en anillo. (Figura 8)
 RED EN ETRELLA (star network):
RED EN ETRELLA (star network):
Red LAN en la que cada dispositivo (nodo) se conecta a una computadora central en una configuración con forma de estrella (topología); normalmente, una red que consta de una computadora central (denominada hub) rodeada por terminales. (Figura 9)
 RED EN ARBOL (tree network):
RED EN ARBOL (tree network):
Una topología para una red LAN en la que una máquina se conecta a una o más de otras máquinas, cada una de las cuales se conectan a una o más de otras, y así sucesivamente, de manera que la estructura formada por la red se parece a un árbol. (Figura 10 )
DESCRIPCIÓN DISPOSITIVOS PERIFÉRICOS EN UNA COMPUTADORA
Los Dispositivos Periféricos son componentes de hardware que acompañan a una computadora para incrementar su funcionalidad para introducir, extraer y almacenar datos. Están ubicados “alrededor de la máquina”. Por ejemplo, el ratón o mouse, el teclado, el monitor, la impresora, lectores de códigos de barra, disco duro, etc.
Los Dispositivos Periféricos se instalan con base en las necesidades del usuario y sus disponibilades económicas. Un Equipo Básico típico que se compre, incluye: Procesador, Memoria RAM, Disco Duro, Unidad de Disquete, Monitor, CD-ROM, Impresora, Teclado y Ratón. Cualquier Periférico adicional que se requiera “se paga aparte”. Se podría sustituir el mouse con una “Esfera Rastreadora” o Track Ball. También es posible aumentar las capacidades de la computadora agregándole un Digitalizador o Escáner para capturar imágenes. Para la conexión a Internet se requiere: Tarjeta de Red, Modem y una Cuenta de Servicio de Acceso a Internet a través de un Proveedor de Servicios Internet (ISP). De manera que las posibilidades de configuración del Equipo de Computación Básico, son muy amplias, dependiendo de cuanto dinero se esté dispuesto a invertir.
 DISPOSITIVOS APUNTADORES (Ratón, Esfera y Lápiz)
DISPOSITIVOS APUNTADORES (Ratón, Esfera y Lápiz)
Estos son dispositivos que ayudan a manipular objetos y seleccionar opciones de menú en la Pantalla. El más conocido es el mouse o ratón como dispositivo apuntador en el Equipo de Computación Básico. Para manejar el Ratón o Mouse, descansa la palma de la mano derecha sobre él, de manera que el dedo índice quede sobre el botón izquierdo. Sujeta el ratón con el dedo pulgar al lado izquierdo, el dedo medio sobre el botón derecho y los dos dedos restantes, anular y meñique, sujetando el lado derecho del mouse. Pruébalo ahora en tu computadora.
Para manejar el Ratón o Mouse, descansa la palma de la mano derecha sobre él, de manera que el dedo índice quede sobre el botón izquierdo. Sujeta el ratón con el dedo pulgar al lado izquierdo, el dedo medio sobre el botón derecho y los dos dedos restantes, anular y meñique, sujetando el lado derecho del mouse. Pruébalo ahora en tu computadora.
Un apuntador del ratón o puntero (normalmente en forma de punta de flecha) se mueve por la Pantalla “en concordancia con los desplazamientos del ratón” sobre una superficie dura, preferiblemente una “almohadilla de desplazamiento del ratón” o mouse pad, sobre la superficie del escritorio.
El ratón tiene tres operaciones fundamentales, a saber:
1. Click en el ratón: es la operación de “oprimir el botón izquierdo una vez” para seleccionar un objeto en la Pantalla.
2. Doble Click en el ratón: se realiza al “oprimir el botón izquierdo dos veces en rápida sucesión” en algunas operaciones con el ratón se requiere dar doble click.
3. Arrastrar con el ratón: es una operación combinada de “Click y Arrastre de un objeto de un lugar a otro en la Pantalla”. Para ello: a) Colocar el Puntero del Ratón sobre el objeto que se va a arrastrar; b) Pulsar el botón izquierdo del mouse y “mantenerlo presionado”; c) Mover el ratón en la dirección de arrastre en la Pantalla para “jalar o arrastrar el objeto hasta su nuevo lugar”; d) Soltar el ratón levantando el “dedo índice derecho del botón izquierdo del ratón”.
LA ESFERA RASTREADORA o “track ball”
Es un dispositivo apuntador alternativo al ratón. Funciona como un mouse de cabeza. El usuario descansa su dedo pulgar en la pelota expuesta y sus dedos en los tres botones. Para mover el Puntero por la Pantalla, se hace girar la pelota con el pulgar. Debido a que no se mueve el dispositivo completo, un track ball requiere menos espacio que un ratón; de manera que cuando el espacio disponible es limitado, un track ball puede ser una solución “a la medida de las circunstancias”. Estos dispositivos se hicieron populares con la llegada de las computadoras laptop, las cuales se suelen utilizar sobre las rodillas o en superficies de trabajo pequeñas sin espacio para un mouse. Por ejemplo, en el asiento de un avión.
Los track balls, tal como ocurre con los ratones, están disponibles en diferentes modelos. En computadoras portátiles, los track balls pueden estar incorporados en forma directa en el teclado, deslizarse fuera de la unidad del sistema en un cajón pequeño o sujetarse con una abrazadera a un lado del teclado.
LÁPIZ ELECTRÓNICO
Aunque el teclado y el ratón son los dispositivos de entrada más utilizados cuando se trabaja en el escritorio, hay otras formas varias de introducir datos en una computadora. A veces, la herramienta tan sólo es cuestión de preferencia del usuario. Sin embargo, en muchos casos, las herramientas usuales pueden resultar poco apropiadas. Por ejemplo, en una fábrica o almacén llenos de polvo, un ratón o un teclado pueden atascarse de suciedad muy pronto.
Los Sistemas de Cómputo basados en lápices usan un lápiz electrónico como su principal dispositivo de entrada. El usuario sostiene el lápiz en su mano y escribe en una almohadilla especial o directamente en la Pantalla (cuando ésta es sensible al tacto) Sistema de Cómputo basado en Lápiz)
EL TECLADOS
El teclado es el principal dispositivo de entrada para introducir texto y números en la computadora. Consta de más o menos 100 teclas, cada una de las cuales envía un código de carácter diferente a la CPU.
Los teclados de computadoras personales vienen en muchos estilos. Los diversos modelos difieren en tamaño, forma y tacto, pero exceptuando unas cuantas teclas para propósitos especiales, la mayor parte de los teclados tienen una disposición casi idéntica. La disposición más común es la conocida como “Teclado Extendido IBM”. Tiene 101 teclas ordenadas en cinco grupos, como se muestra a continuación.
1. Teclas Alfanuméricas (Alphanumeric keys)
2. Teclas Modificadoras (Modifier keys)
3. Teclado Numérico (Numeric keypad)
4. Teclas de Función (Function keys)
5. Teclas de Movimiento del Cursor (Cursor movement keys)
Teclas Alfanuméricas (Alphanumeric keys)
Son parecidas a las teclas de una máquina de escribir, tanto en su aspecto como en su acomodación. Este orden de acomodación común se llama “disposición QWERTY” debido a que las seis primeras letras en la fila superior son precisamente Q, W, E, R, T, Y. Además de las letras, se incluyen los números y los signos de puntuación y símbolos especiales (¡,#,$,%,&,/, etc.).
Teclas Modificadoras (Modifier keys)
Son teclas que se utilizan en combinación con las teclas del teclado alfanumérico, para ejecutar operaciones de “atajos de teclado” o equivalentes de opciones de menú de la interfaz con el usuario. En una PC las teclas modificadoras son: Shift, Ctrl, y Alt.
Teclado Numérico (Numeric keypad)
Se ubica en la parte derecha del teclado, se parece a una máquina calculadora, con sus diez dígitos y sus operadores matemáticos (+, -, *, / ). Este teclado es el preferido por los Cajeros, para realizar entradas de datos numéricos.
Teclas de Función (Function keys)
Las Teclas de Función (F1, F2,...,F12) generalmente están ordenadas en una hilera a lo largo de la parte superior del teclado. Le permiten dar comandos a la computadora “sin teclear series largas de caracteres”. El propósito de cada tecla de función depende del programa o software que se esté utilizando. Por ejemplo, en la mayoría de los programas la Tecla F1 es la tecla para solicitar “Ayuda” contextual. Cuando se oprime, se despliega una Pantalla con información sobre el programa que se está ejecutando.
Teclas de Movimiento del Cursor (Cursor movement keys)
Son teclas que permiten desplazar el cursor en la Pantalla hacia arriba, abajo, derecha, o izquierda. En un Programa de Procesamiento de Palabras, hay una marca en la Pantalla en el lugar donde serán introducidos los caracteres que mecanografíe. Esta marca recibe el nombre de cursor o punto de Inserción, puede aparecer en la Pantalla como un cuadro, una línea o un símbolo que parece una I mayúscula, conocido como cursor en forma de I.
Otras Teclas (Esc, Impr Pant, Bloq Despl, Pausa)
Esc Por lo general, se usa para “retroceder” un nivel en un ambiente multinivel. Por ejemplo, si se abren varias Cajas de Diálogo, uno a partir del otro, se puede oprimir la tecla Esc para cerrarlas en orden inverso.
Impr Pant Esta tecla envía una “imagen” del contenido de la Pantalla en forma directa a la impresora. Sólo funciona cuando hay una visualización en “modo texto en la Pantalla”; no funciona con Programas Gráficos o en Ambientes Gráficos.
Bloq Despl Por lo general, esta tecla controla las funciones de las teclas de movimiento del cursor. Con algunos Programas, Bloq Despl hace que el cursor permanezca estacionario en la Pantalla, y que el contenido del documento se mueva alrededor de él. Cuando se desactiva Bloq Despl, el cursor se mueve en forma normal. Esta tecla no funciona en absoluto en algunos Programas.
Pausa En algunos Programas, esta tecla puede usarse para detener la ejecución de un “comando en progreso”.
ESTUDIO DE INTERFACES GRÁFICAS “amigables con el usuario” (GUI)
Para alcanzar el “dominio instrumental o manejo correcto de la computadora” es necesario que el Usuario se comunique con ella; debe decirle qué tareas ha de ejecutar; interpretar con precisión la información que le presenta en la Pantalla.
Interfaz con el usuario es el medio de comunicación del ser humano con la máquina. A través de esta interfaz, la computadora “acepta las entradas” y “presenta sus salidas”. Estas salidas proporcionan:
• los resultados del procesamiento,
• confirman la terminación del procesamiento o
• indican que ya se almacenaron los datos Los tres medios de comunicación Usuario – Computadora más conocidos de la interfaz son:
Los tres medios de comunicación Usuario – Computadora más conocidos de la interfaz son:
1. Prompts
2. Asistentes
3. Intefaz de línea de comando
Prompt es un mensaje de orientación, que presenta la computadora por la Pantalla, para pedirle al Usuario que haga algo. Algunos son fáciles de entender, como:
“Teclee su nombre completo”
Otros pueden resultar incomprensibles para los Usuarios Casuales, por ejemplo
Para responder a un Prompt el Usuario debe introducir la data solicitada o seguir una instrucción “al pie de la letra”.
Diálogo de Sugerencias es una “secuencia de Prompts” que se utiliza a veces para desarrollar una interfaz con el Usuario.
Asistentes son facilidades de uso que proporcionan los Programas Comerciales Modernos en lugar de Diálogos de Sugerencias. Un Asistente es una sucesión de Pantallas que dirigen al Usuario a través de varias etapas, como:
• Establecer la conexión a Internet,
• Crear una Gráfica de Negocios,
• Arrancar un Escáner, etc.
Comando es una instrucción para que la computadora ejecute cierta tarea o trabajo. Una interfaz que pide al Usuario que teclee comandos se conoce como Interfaz de Línea de Comando con el Usuario. Cada palabra de un comando da lugar a una acción específica por parte de la computadora.
Los Comandos que se introducen deben corresponder a una sintaxis específica. La Sintaxis denota la “sucesión y puntuación de palabras de comandos, parámetros e interruptores”. Si el Usuario “escribe mal una palabra de comando” o si “omite la puntuación requerida” o “teclea palabras fuera de orden”, se producirá un Mensaje de error o Error de sintaxis. El proceso continuará después que el Usuario teclee el comando en forma correcta.
Menu es una Lista de Comandos u Opciones que ayuda a reducir las dificultades de muchos Usuarios “que encuentran muy complicado” recordar las palabras y la sintaxis de los comandos para las interfaces de líneas de comando con el Usuario. Basta con elegir el comando del menú para que la computadora ejecute la tarea correspondiente. Generalmente, se emplean dos métodos para para presentarle al Usuario una “lista razonable de Opciones de Menú”: Uno utiliza Jerarquías y el otro Cuadros de Diálogo.
Jerarquía de Menús es un ordenamiento de Menús clasificados en una relación de superior-subordinado, como en un organigrama. Después de seleccionar una opción en un Menú Principal, aparece un submenú en el cual se pueden hacer más selecciones señalando una opción del mismo, y así sucesivamente en orden de descendencia jerárquica.
Cuadro de Diálogo o Ventana de Diálogo presenta las opciones relacionadas con un comando que aparece como “Opción en un Menú”, por ejemplo en el Menú Archivo la opción Imprimir... (Print...) muestra tres puntos suspensivos para indicar que conduce a una Caja de Diálogo
BIBLIOGRAFÍA BÁSICA:
Parsons, June y Oja, Dan (2000) Conceptos de Computación. Thomson. México
Norton, Peter (2004) Introducción a
Beekman, George (2004) Introducción a
Material Elaborado por: Prof. Luis Ernesto Ramírez
Caracas 6 de marzo de 2005
Adaptado y Modificado: 2009 por Daniela V. Baptista